
Inferential goals: Estimation vs Hypothesis Testing

Inferential goals: Estimation vs Hypothesis Testing

Inferential goals: Estimation vs Hypothesis Testing

Inferential goals: Estimation vs Hypothesis Testing

Inferential goals: Estimation vs Hypothesis Testing

Inferential goals: Estimation vs Hypothesis Testing

Example: Cheating Casino

- A casino, Gimme All Your Bubble Tea Money, has been reported to be cheating and using biased dice with the probability of rolling one not being what it should be.
- How can we investigate that?
- Devise a plan with your neighbor to test this claim.
Example: Macbook pro battery life

Suppose Apple claims that the new Macbook Pro can work for more than 20 hours without a recharge.
- As a YouTuber reviewer, you want to put their claim to the test.
- You randomly select multiple Macbooks and measure how long they hold up without a recharge.
- You find the average time is 21 hours. Does the data support Apple’s claim?
Core idea: test statistic vs null distribution

Age at first marriage - data
- Suppose we want to test if the mean age at first marriage
- \(H_0: \mu = 23\)
- \(H_A: \mu > 23\)
Data modified from Modern Dive: https://moderndive.com/B-appendixB.html

Null distribution
- Null distribution gives us a sense of what would happen if the null model was true
- we can see how common or unlikely observing our sample mean would be under \(H_0\)

Null distribution and \(p\)-value
- \(p\)-value: probability of observing a result as extreme or more extreme towards the alternative hypothesis than what we observed given that \(H_0\) is true
- it describes how unusual the data would be if \(H_0\) were true
- it summarizes the evidence
- We calculate the \(p\)-value as the proportion of simulations that yield a sample statistic at least as favorable to the alternative hypothesis as the observed sample statistic.
- Here \(H_A\): \(\mu > \mu_0\), so we want P(Test Stat \(\geq \bar{X}\))
- P(Test Stat \(\geq\) 23.5)

\(H_A\) and the \(p\)-value
- \(p\)-value: probability of getting something as or more extreme than what we observed
- But what is extreme? It depends on the alternative hypothesis

Conclusion - age at first marriage for US women
- Suppose we chose an \(\alpha = 0.05\)

We estimate the \(p\)-value to be 0.005, thus \(p\)-value < \(\alpha\)
What’s our conclusion?
We reject the null hypothesis
There is evidence that the true average age of first marriage for all US women from 2006 to 2010 is greater than 23 years
Decisions and types of errors

- 2 possible errors can be made in any test
- Type I: reject \(H_0\) when \(H_0\) is true
- Type II: not reject \(H_0\) when \(H_0\) is false
Type I error
Probability of committing a type I error equals the significance level chosen for your test
E.g., for a right-tailed test with \(\alpha = 0.05\):
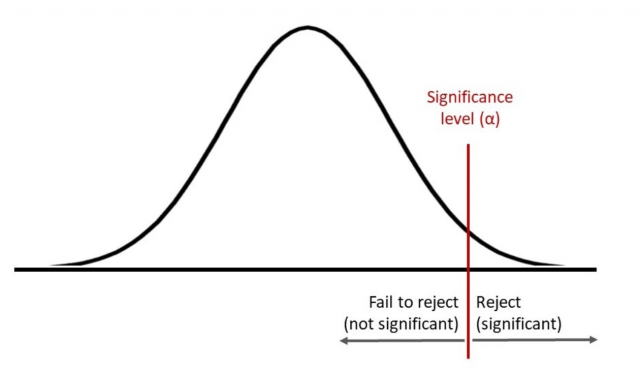
- When our test statistic falls in the rejection region:
- \(p\)-value \(\leq \alpha\), thus \(H_0\) is rejected